Chokecherry Or The Story About 1000000 Timeouts
Chokecherry (https://github.com/funbox/chokecherry) is a wrapper around lager logger which limits the volume of info messages irrespectively of the lager’s backend.
This article tells a story behind this library. Down below you’ll find answers to the following questions:
- “Why it was created?”
- “How it works?”
- “Do I need it?”
The Story About 1000000 Timeouts
We use lager in almost all of our applications. And it works pretty well most of the time, except the cases where it doesn’t.

It all started one day when we were experiencing a peak load in one of the applications (we’ll call it FortKnox). So, FortKnox was processing a lot of data and producing a lot of logs (particularly, info messages). As shown on a picture below, we were writing logs to a file on disk.

Then we started seeing random exits (timeouts in calls to lager:info)
from many places. These led to different parts (gen_servers, gen_fsms, etc.) of
FortKnox crashing. Some of them got restarted by their supervisor. But it was
clear that this won’t last long. Indeed, at some point, it all came down to the
application’s supervisor and whole node stopped working.
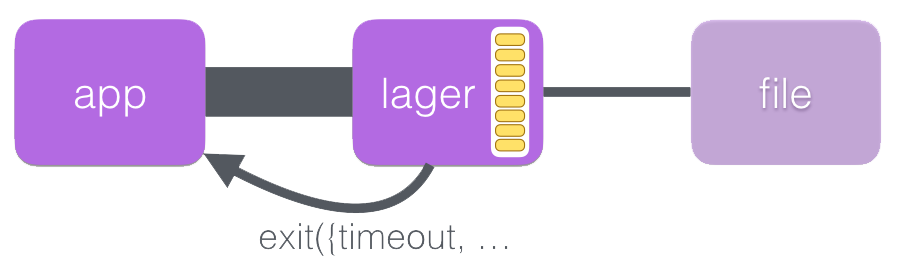
This is what happened. Hard disk was not able to handle so much writes (even in the presence of OS caches). file:write became slower and lager’s message box started to grow in size. The behavior for lager, in that case, is to switch to synchronous mode (see https://github.com/basho/lager#overload-protection for details), what he did. That’s how we came to the random exits.
Possible solutions were (discussion on erlang-russian):
RAM disk(high cost of maintenance)configure lager in such a way, that would fix the problem(no way to do that)use tmpfs for(low cost of maintenance; difficult to setup syncing tmpfs to disk; some logs still could be lost)/tmp- create a thin wrapper around lager (low cost of maintenance; easy to setup; some logs may be dropped)
On lager settings
lager has many settings and we could play with them. For example, we could turn off synchronous mode.
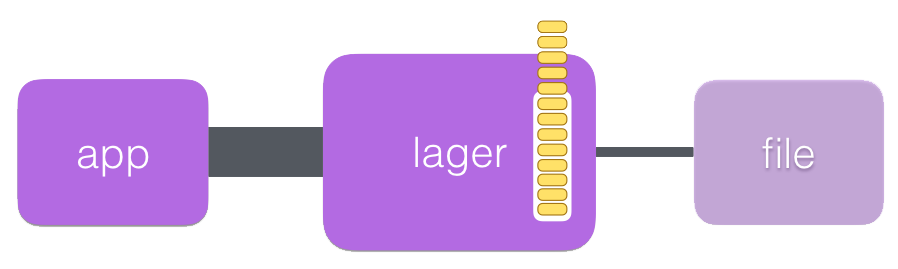
What will happen then is lager’s mailbox start growing and, eventually, when there will be no more free memory, node will crash.
For performance, the file backend does delayed writes, although it will sync at specific log levels, configured via the `sync_on’ option. By default the error level or above will trigger a sync.
Keep in mind that there were an exessive amount of info messages, so no fsync
calls (file:datasync) were made (we didn’t change the default).
So there was no simple solution for this problem. That’s why we created chokecherry. What follows is how it works.
Chokecherry
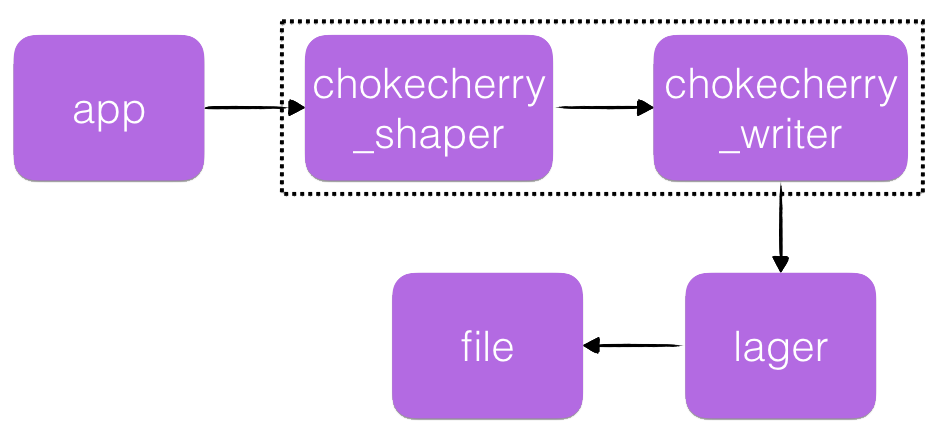
shaper accumulates incoming messages in the queue. If the queue size
exceeds log_queue_capacity within a certain time period (1 second), it sends
an error_report “chokecherry dropped N messages in the last second”, and drops
messages from the end of the queue, while receiving new ones and maintaining
the maximum size of the queue.
writer pulls messages from shaper and transmits them to lager.
Default settings are as follows:
[
{chokecherry, [
{shaper, [
{timeout, 1000},
{log_queue_capacity, 10000}
]}
]}
].
Do you need it
If your application produces a lot of logs and you can afford to lose some (i.e. stable work of an application is more important to you) - yes.
In the above story, we were writing logs to a file using lager_file_backend.
This doesn’t mean that a similar story could not happen to you if you’re using
a different backend. So it may be applicable to other backends likewise.
Source code
Currently, we are only “shaping” info messages. If you think we should do it for warning and error, or make it optional, let us know.
Source code: https://github.com/funbox/chokecherry