Зависла Erlang нода. Что делать?

Пишу статью по горячим следам. Пару дней назад тестировал работу приложения при пропаже соединения с Redis’ом. Так вот, после возобновления соединения (успешном переподключении), через раз приложение зависало полностью. Ни консолью подрубиться, ничего…
Обычно такое происходит, если вы используете C-расширение, оформленное в виде NIF, и оно в один прекрасный момент блокируется. Шедулер Erlang в таком случае не может прервать выполнение потока, как он поступил бы в случае с Erlang кодом.
Всякие Linux утилиты (типа strace) нам мало о чем скажут. Как дебажить
C-расширения в Erlang тоже непонятно (отдельно - понятно, gdb и тому
подобное). Если знаете - напишите плиз.
Зато мы можем послать сигнал виртуальной машине Erlang и она создаст crash dump:
$ kill -SIGUSR1 <pid>
Crash dump is being written to: erl_crash.dump...done
Received SIGUSR1
Смотреть на него без дополнительных утилит еще более болезненно, чем на вывод
tcpdump без Wireshark.
Анализируем crashdump
Мне известны по крайней мере 2 инструмента: crashdump_viewer и recon.
crashdump_viewer
http://erlang.org/doc/apps/observer/crashdump_ug.html
$ erl
> crashdump_viewer:start().
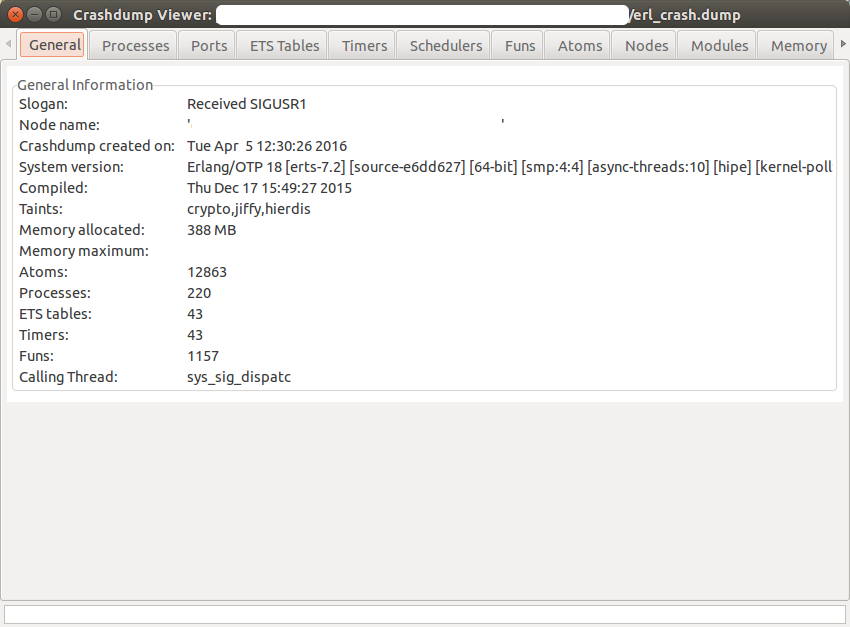
Общая информация.
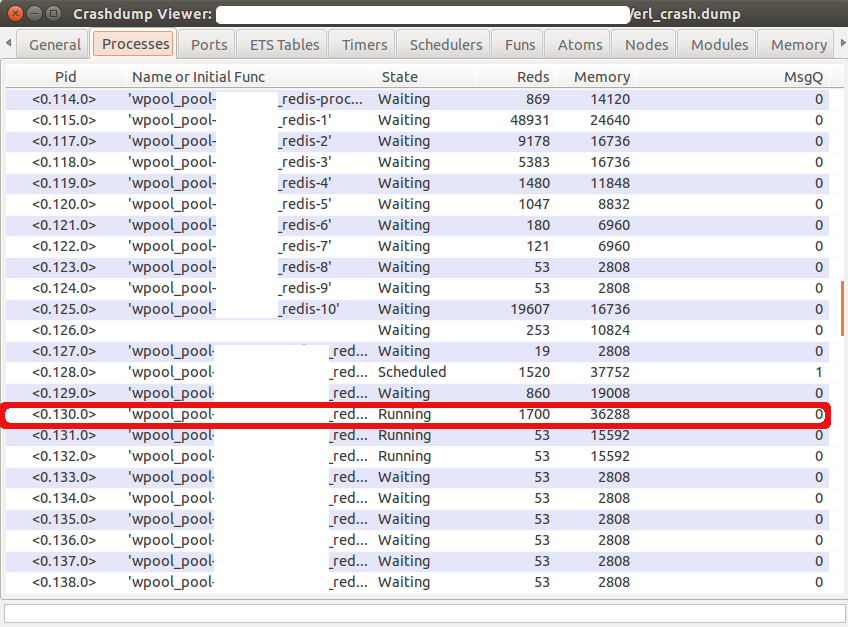
Список процессов.
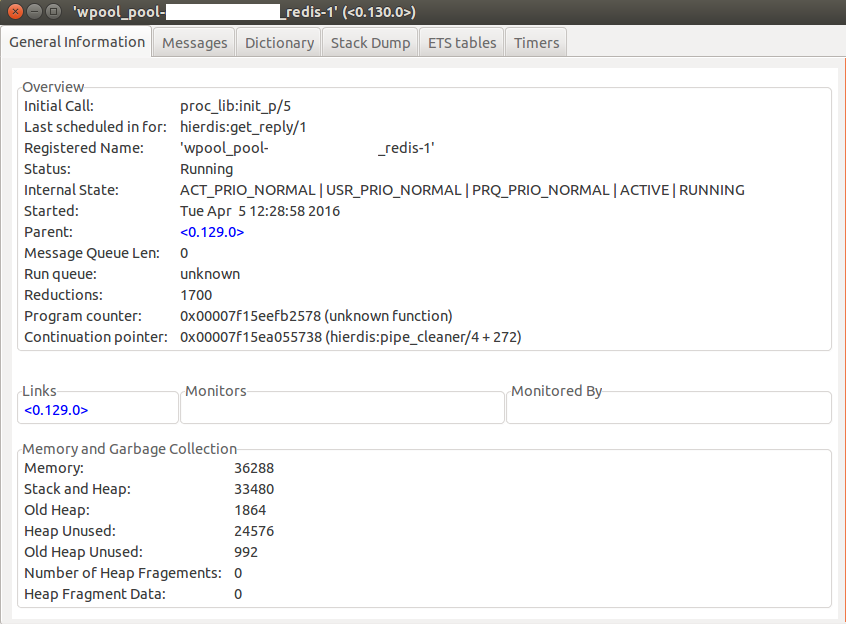
Информация по одному из немногих запущенных процессов с большим количеством редукций. Чтобы найти конкретный процесс, внутри которого произошла блокировка, пришлось просмотреть несколько штук (количество запущенных процессов обычно = числу ядер).
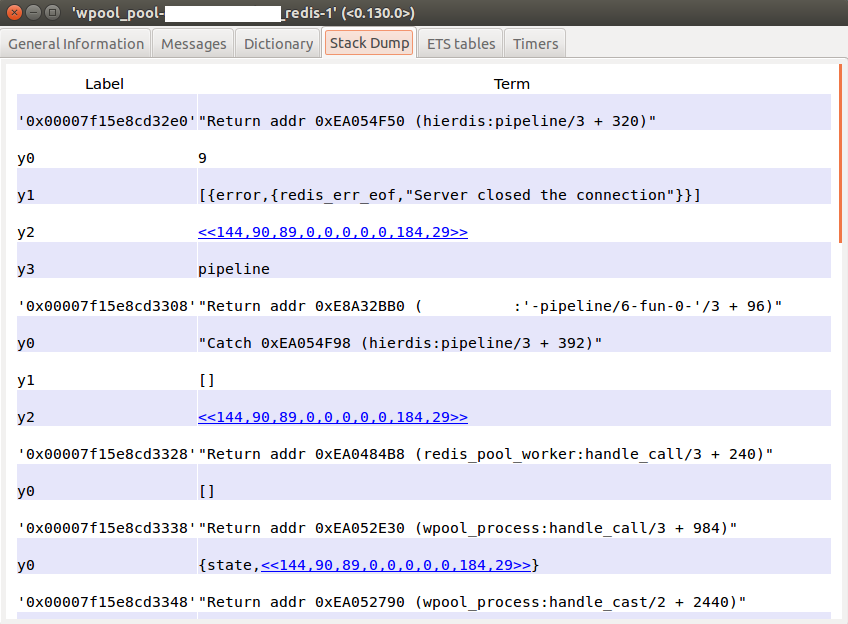
stackdump процесса.
Как видно из 2-й картинки выше мы заблокировались на
hierdis:pipeline_cleaner/4 (см. “Continuation pointer”).
Hierdis - это клиент для Redis, который мы
используем. Далее оставалось делом техники воспроизвести вызов (подсмотреть
аргументы можно либо в crashdump_viewer, либо используя
recon_trace) в самом клиенте и
найти конкретную причину (PR).
recon
./recon/scripts/erl_crashdump_analyzer.sh <crashdump>
analyzing erl_crash.dump, generated on: Tue Apr 5 12:30:26 2016
Slogan: Received SIGUSR1
Memory:
===
processes: 374 Mb
processes_used: 374 Mb
system: 14 Mb
atom: 0 Mb
atom_used: 0 Mb
binary: 0 Mb
code: 8 Mb
ets: 0 Mb
---
total: 388 Mb
Different message queue lengths (5 largest different):
===
3 1
217 0
Error logger queue length:
===
0
File descriptors open:
===
UDP: 2
TCP: 8
Files: 4
---
Total: 14
Number of processes:
===
220
Processes Heap+Stack memory sizes (words) used in the VM (5 largest different):
===
1 10695351
2 8912793
1 3581853
1 2487399
2 2072833
Processes OldHeap memory sizes (words) used in the VM (5 largest different):
===
1 7427328
1 514838
1 121536
2 28690
1 10958
Process States when crashing (sum):
===
4 Current Process Internal ACT_PRIO_NORMAL | USR_PRIO_NORMAL | PRQ_PRIO_NORMAL | ACTIVE | RUNNING
4 Current Process Running
3 Internal ACT_PRIO_MAX | USR_PRIO_MAX | PRQ_PRIO_MAX
2 Internal ACT_PRIO_MAX | USR_PRIO_MAX | PRQ_PRIO_MAX | TRAP_EXIT
90 Internal ACT_PRIO_NORMAL | USR_PRIO_NORMAL | PRQ_PRIO_NORMAL
4 Internal ACT_PRIO_NORMAL | USR_PRIO_NORMAL | PRQ_PRIO_NORMAL | ACTIVE | RUNNING
3 Internal ACT_PRIO_NORMAL | USR_PRIO_NORMAL | PRQ_PRIO_NORMAL | IN_PRQ_NORMAL | ACTIVE | IN_RUNQ
118 Internal ACT_PRIO_NORMAL | USR_PRIO_NORMAL | PRQ_PRIO_NORMAL | TRAP_EXIT
4 Running
3 Scheduled
213 Waiting
Он дает общую картину того, что происходит.
Вообще recon довольно полезная библиотека. В ней можно найти различные модули для инспекции состояния ноды, трассировки и т.д.
Вот например скрипт, который показывает работающие (running) процессы с
количеством сообщений в mailbox’е >= threshold:
$ awk -v threshold=1 -f ./recon/script/queue_fun.awk erl_crash.dump MESSAGE QUEUE LENGTH: CURRENT FUNCTION
======================================
1: gen_server:loop/6
1: gen:do_call/4
1: gen:do_call/4