Why Do You Need a Pool
There are a number of reasons you may want to use a pool of workers in your application.
1) Distribute work across all available CPUs.
For that, we create fixed number of threads with the desired level of parallelism = the number of available cores of the host’s CPU. Example in Java.
ExecutorService executor = Executors.newFixedThreadPool(4);
This may require some tuning. A number of threads could be increased or decreased. Alternately, you could switch to WorkStealingPool if fork/join model better suits your needs. Refer to https://docs.oracle.com/javase/8/docs/api/java/util/concurrent/Executors.html for more information.
2) Open N connections to an external resource (typically, a database)
This gives us a lot of benefits (some of them are not so obvious):
- we do not spend time on opening the connections (if we’re creating a TCP connection, handshake could take up to 750 ms)
- it is much easier to support the code since all operations with the particular resource happen in one place
- it is much easier to analyze the current application’s state (number of connections, etc.)
- we improve throughput by sharing the network latency
I think, only the last one requires explanation, others are pretty obvious.
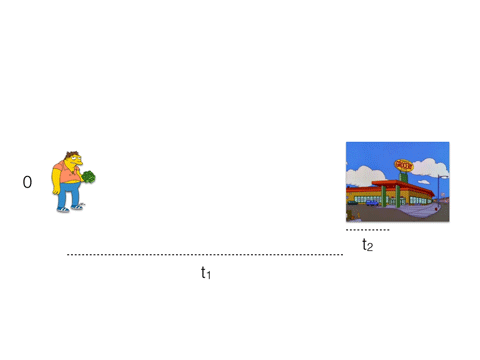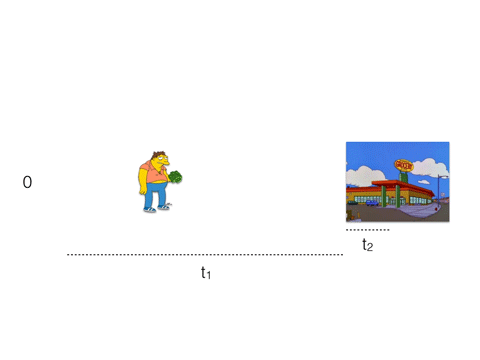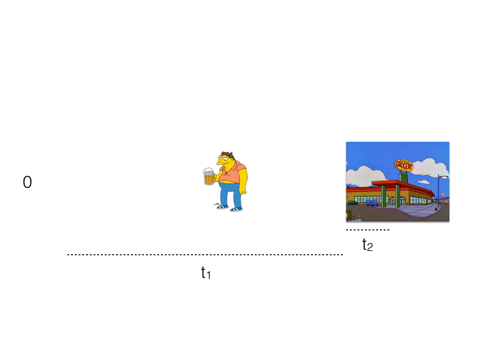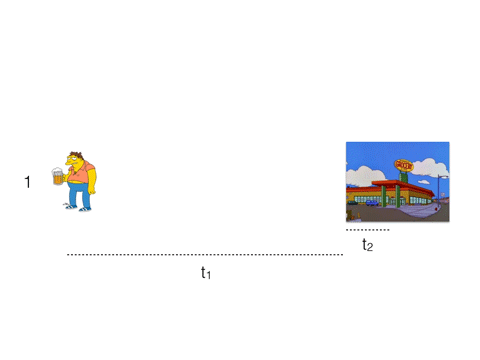
Our friend Barney here wants to buy some beer, so he takes a long walk to the nearest store. It will take him 3 * (t1 + t2) to buy 3 beers.
t1 is a network latency, t2 - processing time.
What if instead, he and his buddies will go to the store together. Even if the store has only one cash register (like Redis) and the cashier serve them in turn, they will buy 3 beers in t1 + 3 * t2.
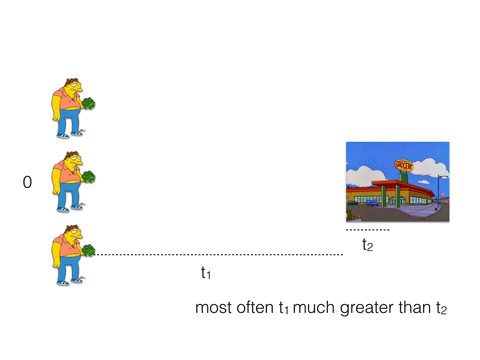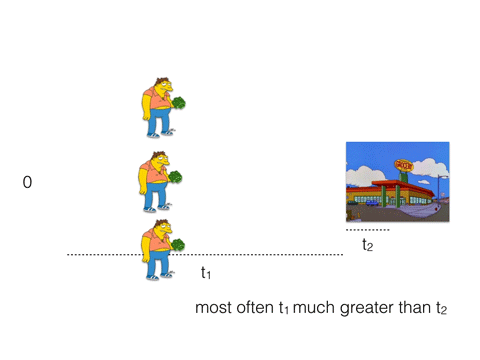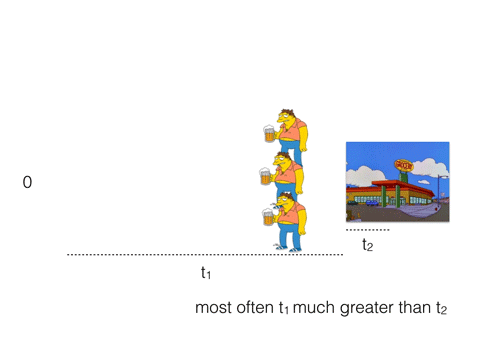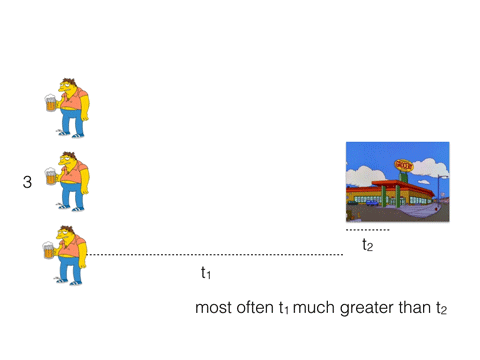
Most often t1 much greater than t2. Therefore, t1 + 3 * t2 < 3 * (t1 + t2).
In other words, it is better to send N requests in parallel comparing to
sending one by one because the network latency is greater than time to process
a request.
If you have any comments, you could leave them below or send me an email.